Are comments supported in your source code manager (SCM)?
PR or MR comments are currently supported for:- All GitHub plans
- All GitLab plans
- All Bitbucket plans
- Azure DevOps Cloud repositories
- Any other SCM or repository provider
Have you configured permissions and tokens correctly?
GitHub
Semgrep relies on the Semgrep GitHub app to make comments on code. To receive comments on a project, ensure that you have performed the following steps:- You have onboarded the project to Semgrep AppSec Platform.
-
You have configured your GitHub app with permissions for all repositories that are scanned by Semgrep AppSec Platform. See Enabling GitHub pull request comments for details, or review the following examples:
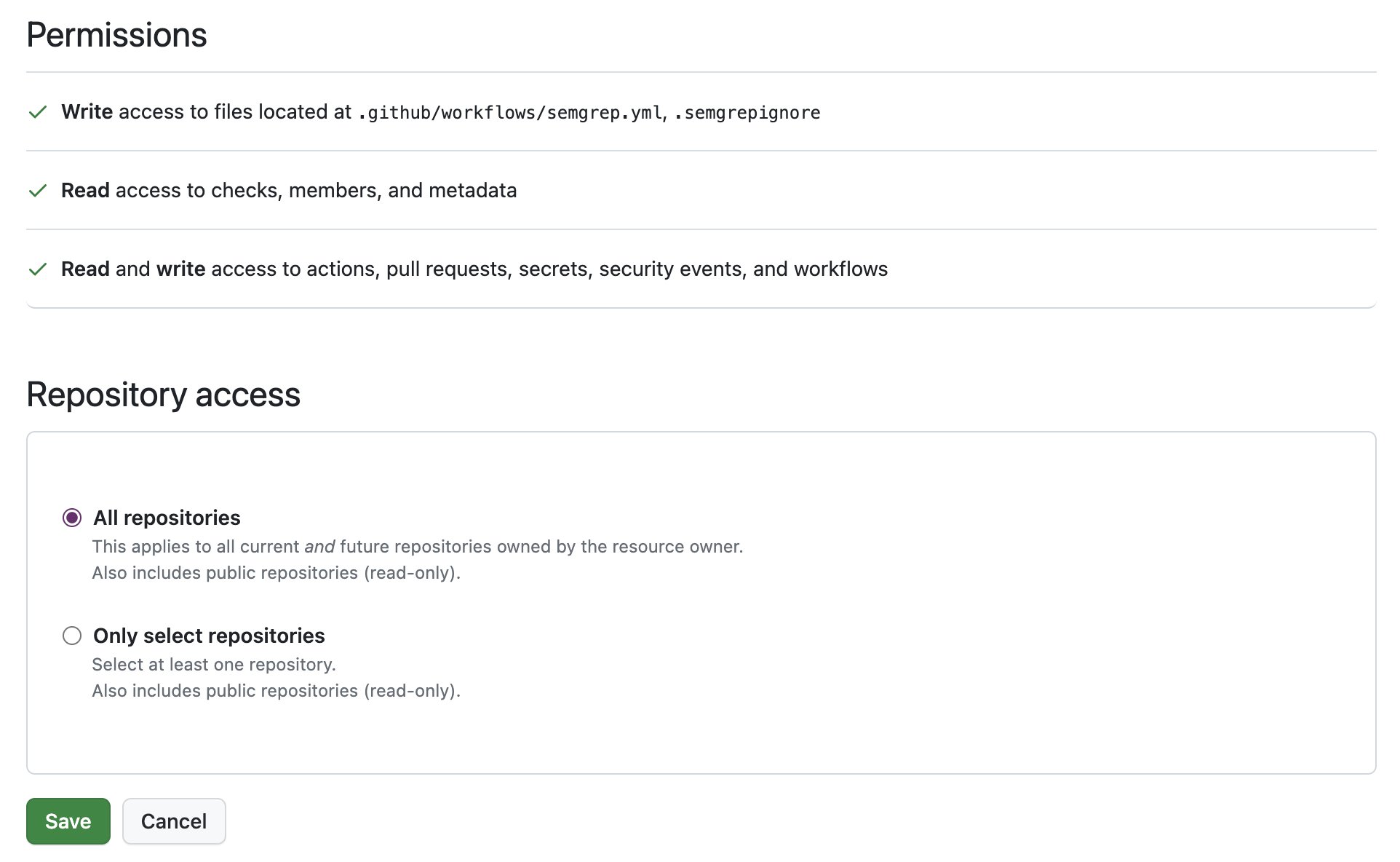
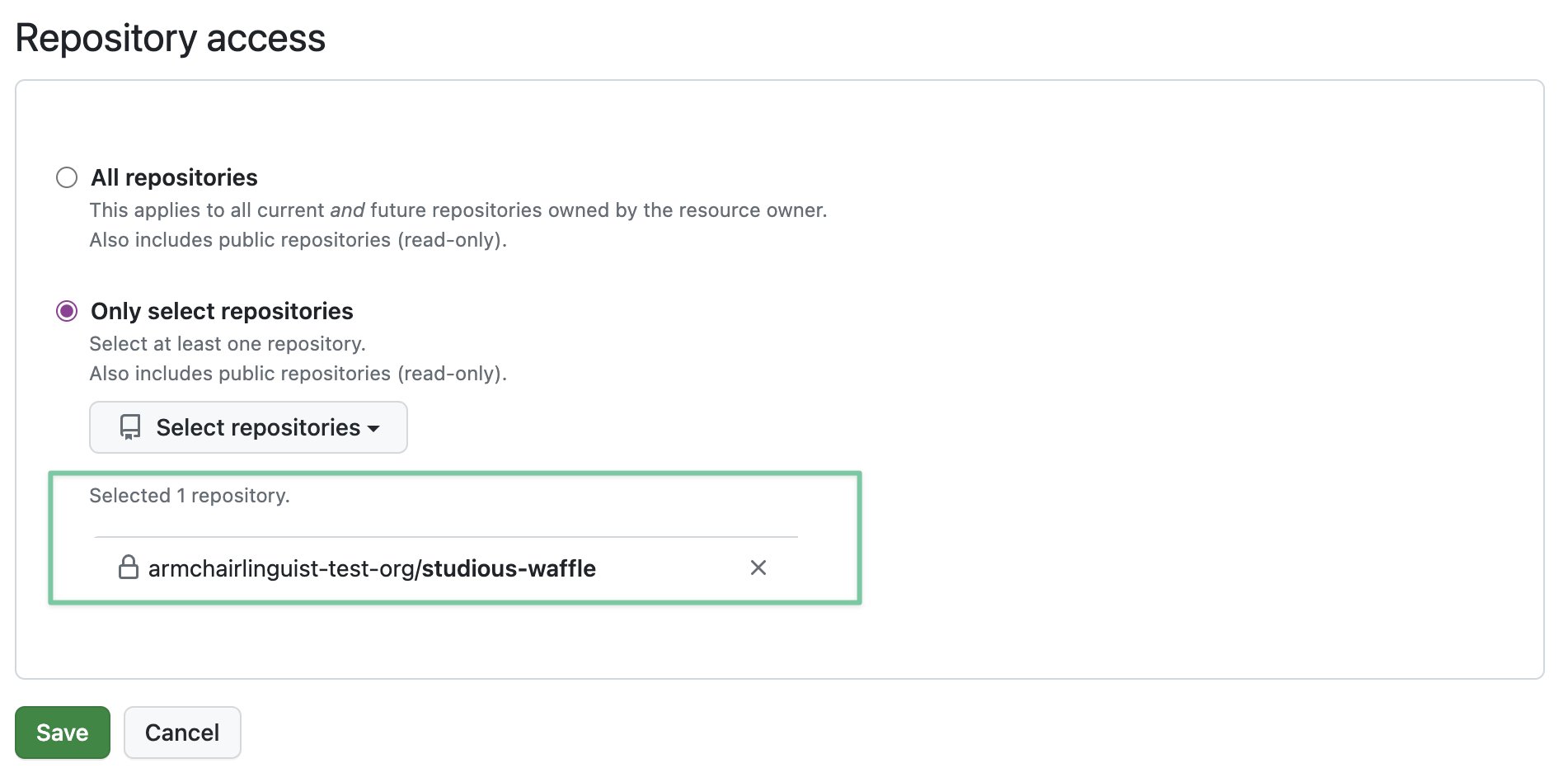
Azure DevOps
See Enable Azure pull request comments for token permissions and configuration guidelines.GitLab
The GitLab token should haveapi scope. See Enable GitLab merge request comments for details.
The api scoped token must be provided to Semgrep through the SCM connection. Semgrep no longer supports tokens provided in the GitLab CI/CD pipeline.
Bitbucket
The Bitbucket token must be a repository access token or a workspace access token. See Enable Bitbucket pull request comments for details.Are you running diff-aware scans?
In Managed Scans: Semgrep always runs diff-aware scans on pull and merge request events. Full scans run at scheduled intervals. In GitHub Actions and GitLab CI/CD: Semgrep runs diff-aware scans on pull or merge requests by default if you are using the recommended configuration. In other SCMs or CI systems, or with unusual pipeline configurations: diff-aware scans may require additional setup. Review the configuration instructions for your SCM or custom configuration for your CI jobs and ensure you have configured your scans correctly.Identify a diff-aware scan
Semgrep diff-aware scans are most easily identified by reviewing three items in the scan log:- The triggering event
- The number of files scanned
- Whether a baseline scan is conducted
The triggering event for the scan
The triggering event for the scan in GitHub or GitLab should typically bepull_request. This is the easiest to find but the least reliable, since it’s possible to configure diff-aware scans on other event types. In the scan log, this appears as:
The number of files scanned
The number of files scanned should be approximately the number of files modified in the PR, and should not include all files in the repository. In the scan log, this appears as:Whether a baseline scan is conducted
Finally, during the process of a diff-aware scan, Semgrep actually conducts two scans: one at the current tip or head of the PR, and one at the baseline ref or commit. The following log is anonymized and truncated for clarity, and the exact format of the log may evolve over time. It shows the key item to review, the two distinctScan Status entries:
fcc...d21, scans 52 files and identifies 60 findings. The baseline scan, which occurs at 104...950, scans 4 files. Baseline scans typically scan fewer files than the original scan, as they only need to scan files and rules that have findings in the initial scan to determine which of those findings were present before the changes made in the pull or merge request.
This also means that baseline scans are not conducted if all findings in the current commit that are in files added by the PR or MR, because those findings could not have been present before. This information is logged as: